A website can implement CAPTCHA blocking by using a web form that the user must submit to gain access to any restricted areas of the site. The web form is usually quite simple, consisting of an image element and a text box element. The image displays some characters which the user must enter into the text box in the exact sequence as given in the image. A human user can read the text in the CAPTCHA image, but a web-scraping agent requires special character recognition software to successfully discern the characters in the image.
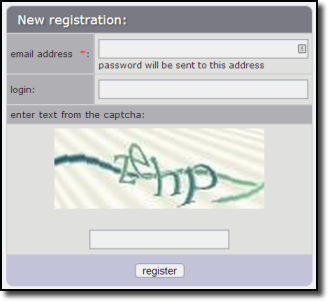
A typical registration form with CAPTCHA blocking
Content Grabber performs both manual and automatic data extraction from websites that implement CAPTCHA blocking. Automatic data extraction requires an account with a third-party CAPTCHA recognition service and, typically, there is a small fee for processing each CAPTCHA image. Manual data extraction is free, but requires you to manually decode CAPTCHA images while running a data extraction agent.
Use a Resolve CAPTCHA composite command to add a number of sub-commands that can be used to process standard CAPTCHA images.
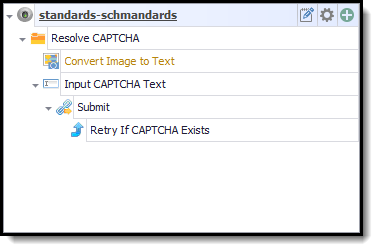
Content Grabber has integrated support for the following CAPTCHA recognition services.
Troubleshooting
If CAPTCHA fails when entering a correct CAPTCHA it may be caused by the following issue.
Content Grabber cannot directly get the CAPTCHA image from the web browser, so it downloads the image a second time, and that may be disallowed by the web server, especially if you are using a proxy rotation service where a new IP address maybe assigned for the image download. To overcome this problem, you can use a Download Screenshot command instead of a Download Image command, in which case a second image download is not required.