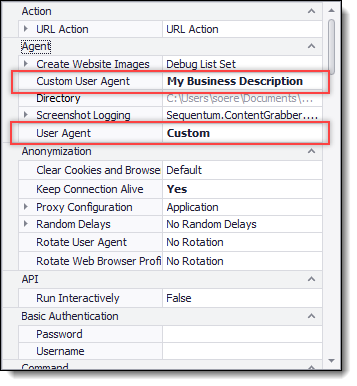
Some websites use a robots.txt file to tell robots how they are allowed to navigate a website. A robots.txt file contains a list of User Agents and associated paths the User Agents are allowed, or disallowed, to follow. If you decide to obey robots.txt rules, you should configure your agent to use a custom User Agent that describes your business, so website publishers can decide to allow or disallow your agents to follow certain paths on their websites.
You can configure an agent to always obey Robots rules and block URLs that a robots.txt file disallow, or a page warning can be generated during design time when navigating to a URL that is disallowed. You can also choose to never obey Robots rules.
If an agent is using a Dynamic Browser, Content Grabber will only check Robots rules on URLs loaded in the main browser frame. URLs loaded in sub-frames and IFrames will not be validated.
Robots rules can be configured on the Agent Properties panel.
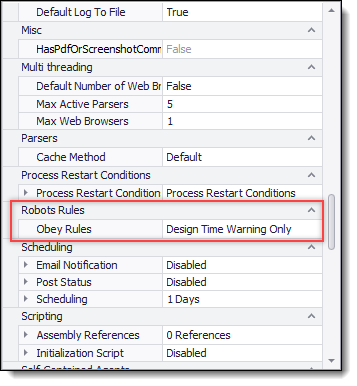
Agent Properties panel.
A custom User Agent can also be configured on the Agent Properties panel.