The Crawl Website command Crawls a website by following all links found on the website. The number of links can be limited by domain name, link depth or number of URLs. The command selects all links by default, but the web selection can be modified, so it only selects specific links.
The Crawl Website command is often used to scan a website for certain information, such as emails, addresses and phone numbers.
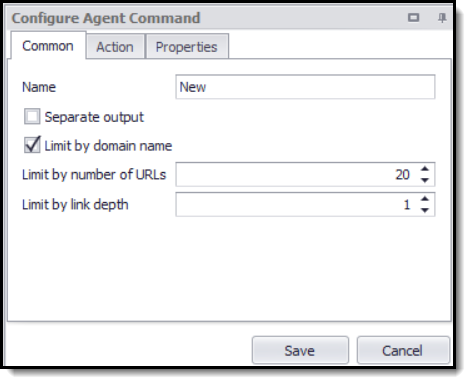
Crawl Website configuration screen.
The Crawl Website command provides the data fields URL and Depth, which can be captured with a Data Value command.
The Crawl Website command uses a HTML Parser, not a Dynamic Browser, by default. This can be changed in the Action tab, but a HTML Parser is recommended to ensure good performance.