We provide this brief introduction for those who are new to web-scraping. If you are familiar with web-scraping, then you many want to begin by reading the article Installing Content Grabber.
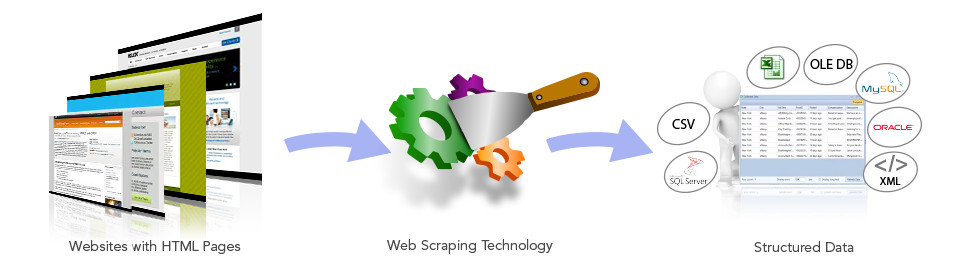
Web-scraping is the process of extracting data from websites and storing that data in a structured, easy-to-use format. The value of a web-scraping tool like Content Grabber is that you can easily specify and collect large amounts of source data that may be very dynamic (data that changes very frequently).
Usually, data available on the Internet has little or no structure and is only viewable with a web browser. Elements such as text, images, video, and sound are built into a web page so that they are presentable in a web browser. It can be very tedious to manually capture and separate this data, and can require many hours of effort to complete. With Content Grabber, you can automate this process and capture website data in a fraction of the time that it would take using other methods.
Web-scraping software interacts with websites in the same way as you do when using your web browser. However, in addition to displaying the data in a browser on your screen, web-scraping software saves the data from the web page to a local file or database.
You can configure web-scraping agents to run on multiple websites, and you can schedule each agent to run automatically. It's easy to configure your agent to run as frequently as you like (hourly, daily, weekly, monthly) to ensure that you are capturing the very latest data.