A Content Grabber agent normally follows a specified path through a website when extracting content. This is much faster than crawling an entire website to look for the content, because page loads are the main performance bottleneck when extracting data, and crawling an entire website will normally result in many more page loads than following a specified path through the website.
Sometimes it may not be possible to specify a fixed path through a website, since you may not know exactly where to find the content that you want to extract. For example, you may want to extract all email addresses on a website, but the email addresses could be located anywhere on the website, so the only option is the crawl the entire website and look for email addresses to extract.
Content Grabber does not contain any built-in web crawling feature, but it's possible to configure a set of commands that works like a web crawler. The command setup is not trivial and requires some scripting, but it's very flexible and performs well.
The Content Grabber template library contains a default set of commands you can use as a basis for your own website crawler. The default command template extracts email addresses from websites, but you can easily change that so it extracts any other content.
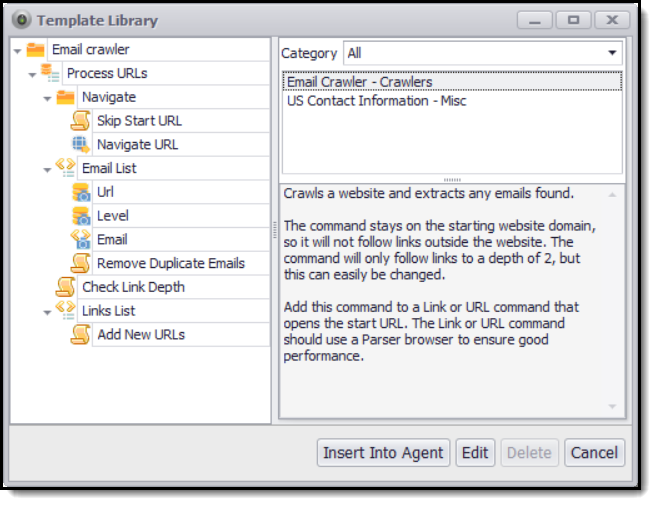
Default web crawler template.