Websites generally provide most of their content in HTML format, but some websites may also provide content in other formats - such as PDF or Microsoft Word documents. Since Content Grabber can only process HTML documents, it will simply download any non-HTML document. Content Grabber can help you extract text and images from within a PDF or Word document by converting such documents into HTML.
To have Content Grabber convert your non-HTML document, you will need to provide an external document converter. The Content Grabber public website provides a list of open source programs that you can use for this purpose. Please remember that we don't support these tools, and you must comply with the license for any conversion tool.
Limitations
The design of most file formats, including PDF and Word files, doesn't include ease-of-conversion to HTML. So, the conversion output is considerably more difficult to manage than standard HTML. In many cases, you'll have to select the entire HTML page and then use Regular Expressions to extract the target content.
Installing a Document Converter
Content Grabber uses a custom script that makes a call to an external document converter, and you can configure this script to call any type of program. The default script can handle the two document converters currently available for download on the Content Grabber website.
Installing the PDF To HTML Converter
Follow these steps to install the PDF-to-HTML document converter:
1.Download the pdftohtml.zip file from the Content Grabber website:
https://contentgrabber.com/web-scraping-tools
2.Extract the content of the zip file into the default Content Grabber Converters folder, My Documents\Content Grabber\Converters. You can also copy the converter into the corresponding Public Documents folder if you need the converter to be available for all users on the computer.
3.The direct path to the document converter should now be:
My Documents\Content Grabber\Converters\pdftohtml\pdftohtml.exe
Installing the Docx To HTML Converter
Follow these steps to install the docx to HTML document converter:
1.Download the docxtohtml.zip file from the Content Grabber website:
https://contentgrabber.com/web-scraping-tools
2.Extract the content of the zip file into the default Content Grabber Converters folder, My Documents\Content Grabber\Converters. You can also copy the converter into the corresponding Public Documents folder if you need the converter to be available for all users on the computer.
3.The direct path to the document converter should now be:
My Documents\Content Grabber\Converters\docxtohtml\docxtohtml.exe
Using a Document Converter
You'll need to add the custom script (that calls the document converters) to a Download Document command, and that same command must also perform the download of the document.
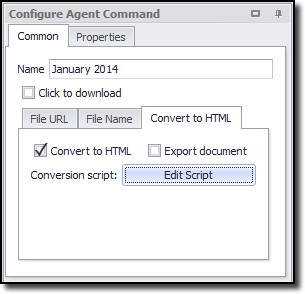
The default conversion script looks like this:
using System;
using System.IO;
using Sequentum.ContentGrabber.Api;
public class Script
{
//See help for a definition of ConvertDocumentToHtmlArguments.
public static bool ConvertDocumentToHtml(ConvertDocumentToHtmlArguments args)
{
if(args.DocumentType=="pdf")
ScriptUtils.ExecuteCommandLine(@"Converters\pdftohtml\pdftohtml.exe",
args.DocumentFilePath, args.HtmlFilePath, "-noframes");
else if(args.DocumentType=="docx")
ScriptUtils.ExecuteCommandLine(@"Converters\docxtohtml\docxtohtml.exe",
args.DocumentFilePath, args.HtmlFilePath, "");
if(!File.Exists(args.HtmlFilePath))
return false;
return true;
}
}
Extracting Content From a Converted Document
After converting a document to HTML, that document goes into the agent data folder and you can use a Navigate URL command to open the HTML document. The Download Document command that did the conversion will also store the path to the document, and then the Navigate URL command can use that path to get the file URL to the HTML document.
An agent with a URL command that links to a
converted HTML document
The Navigate URL command uses data from the Download Document command, so the Download Document command must execute first. Also, both the commands must have the same parent command, or the Navigate URL command must be a child command of the command that contains the Download Document command.
You can execute the Navigate URL command in the editor to open the converted HTML document, but you must first execute the Download Document command to make sure the HTML document is available.
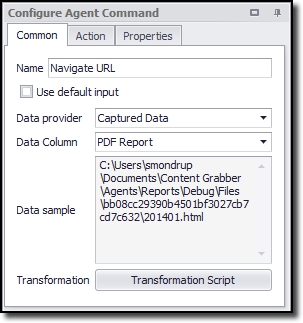
A Navigate URL command using data captured by a
Download Document command