Logging can be used when debugging or running an agent to collect information about the web scraping process. Logging can be set to three different detail levels, low, medium and high. Low detail level only logs errors, medium detail level logs errors and warnings, and high detail level logs errors, warnings and general progress information. Debug logging is always set to high detail level and cannot be changed.
Debug log data is stored in a separate data store, so it doesn't overwrite or get mixed with normal log data.
Debug logging can be turned on in the Debug ribbon menu.
Normal logging can be turned on when running an agent on the Run Agent screen.
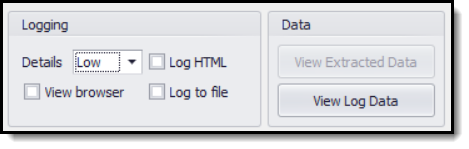
The Run Agent screen is not displayed when running an agent using the Run button in the application menu, so you will not be able to configure logging when running an agent this way.
Logging Raw HTML
Content Grabber automatically logs direct links to processed web pages when logging is turned on, so it's normally easy to view specific web pages that have been processed. For example, if an error or warning appears in the log, you can simply click on the associated URL to open the web page and see if there is anything special about the page that may cause an error.
Sometimes it's not possible to open a web page using a direct URL. For example, some websites implement CAPTCHA protection, which is web pages that appear randomly to ask the user to enter a verification code. If a CAPTCHA page is retrieved instead of a normal web page, your agent is likely to encounter errors, but if you click on the associated URL later, you may not get the CAPTCHA page because it appears randomly. In this case it may be difficult to determine what is causing the error, but you can use the Log HTML feature to log the raw HTML of all processed web pages, and this will allow you to view the CAPTCHA page. Please see the CAPTCHA topic for more information about CAPTCHA.
Error Handling
Please see the Error Handling topic for more information about error handling, notifications and logging.