Typically, the Web Element Content command is the most common, since it is the command that captures text content from the target web page. The command allows you to choose which type of text to extract from a particular web element.
The properties shown in the following table are available to all Web Element Content commands:
Text Option |
Description |
Text |
This is the text that displays in the web browser, and is the most common choice (it's also the default). |
Formatted Text |
This option will extract the entire HTML of the chosen web element and insert line breaks where appropriate. |
HTML |
This option will extract the entire HTML of the chosen web element, including the HTML of any child elements. |
Clean HTML |
This option will extract the HTML, but remove all attributes that are used to style the HTML. |
Styled HTML |
This option will extract the HTML, but remove all attributes that are used to style the HTML, except attributes used for inline styling. |
Inner HTML |
The entire HTML of all child elements of the selected web element, but not the tag HTML of the chosen element itself. |
Tag Text |
The text of the selected web element, excluding the text of any child elements. |
Unique ID |
A unique identifier. The web selection is ignored if this option is selected. |
Default File Name |
Returns any file name specified by a response from a web server. If no file name is specified, extracts a file name from a href attribute, or a unique identifier if the href does not not exist.
This attribute is mostly relevant to file capture commands. |
Node Position |
The position of the web elements among all siblings. |
Position |
The position of the web element among siblings of the same type. |
In addition to the default options given above, some web elements may have other attributes available, such as Class, Name, ID, Value, URL, etc. If a web element has an attribute that is not shown in the default drop down box, then you can simply enter the name of the attribute you want to extract.
The figure below shows the Command Properties panel after choosing Web Element Content from the New Command drop-down:
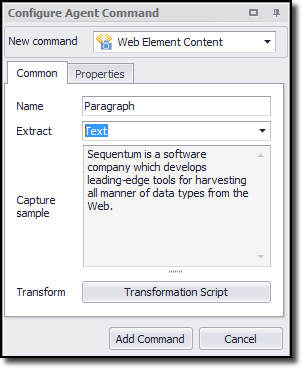
Extracting URLs deserves a special mention. That's because it's more common to extract a link URL instead of navigating to the link, or to extract an image URL instead of downloading the image itself. If you want to extract a URL from a web element, simply select the element and extract the URL or Image URL attribute. You can also enter the actual HTML tag attributes: src for images and href for links. However, the URL and Image URL attributes automatically convert any relative URLs to absolute URLs-which is best in most cases.
Content Transformation Script
The Web Element Content command allows you to use regular expressions or a .NET script, to transform the extracted content. In most cases we recommend that you write expressions or use a script to clean the data that you extract. You can also separate data-such as the elements of a postal address-into separate fields.
Example: Consider a case in which you want to extract product data that includes a price of $400. You could use a transformation script to strip off the "$" character and leave only the numeric value.
Please see the Content Transformation Script topic for more information.